Drawing mode (d to exit, x to clear)
class: middle, title-slide .cols[ .col-1-2[ # From Specialized to General Intelligence ## CDS DS 595 ### Siddharth Mishra-Sharma [smsharma.io/teaching/ds595-ai4science](https://smsharma.io/teaching/ds595-ai4science.html) ] .col-1-2[ .center.width-70[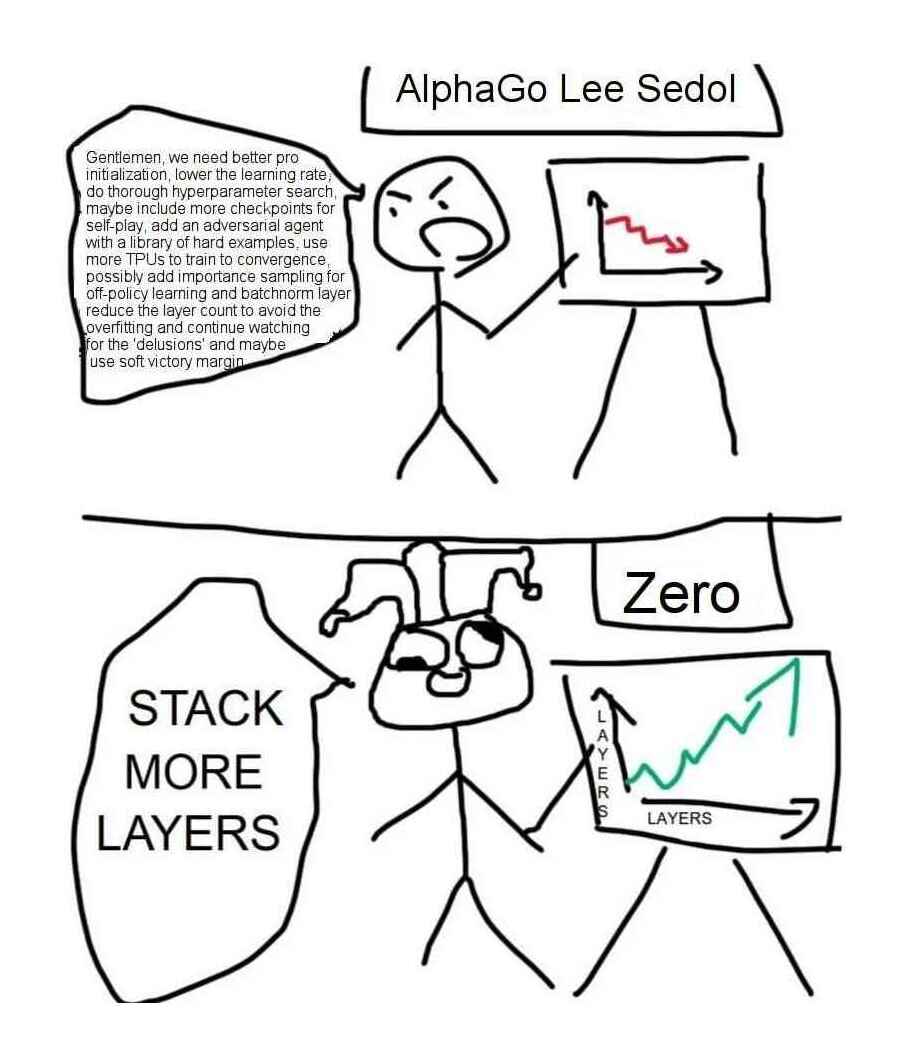] ] ] --- # Assignment 3 (jet generative model) leaderboard | Rank | Name | W1 | |------|------|----| | 1 | Vincent Li | 0.02055 | | 2 | Yiming Li | 0.02065 | | 3 | Sungjoon Park | 0.02078 | | 4 | Marcela Izquierdo Poza | 0.02657 | | 5 | Leonardo Mattos Martins | 0.03889 | --- # Final project: Evaluating and improving LLM scientific capabilities In teams of 2–3: - Identify a **scientific capability** that LLMs struggle with - Build a **rigorous eval** to measure this capability - **Fine-tune** a model to improve it [Instructions PDF](https://bu-ds595.github.io/course-materials-spring26/notes/final-project.pdf) 35% of grade --- # Timeline | Date | Milestone | |------|-----------| | Mon Mar 30 | Project released. Start team formation. | | Fri Apr 3 | Teams finalized (randomly assign unassigned folks) | | Mon Apr 13 | **Proposal due** | | Apr 13–28 | Build eval, collect data, fine-tune, iterate | | Wed Apr 29 | **Presentations** | | Fri May 1 | **Writeup due** | --- # Deliverables **Proposal** (Mon Apr 13): capability + evidence that frontier models fail + eval plan + data plan (Feedback...) **Presentation** (Wed Apr 29): ~8 min per team **Writeup** (Fri May 1): GitHub repo with code, eval, results, README --- # Tinker You'll fine-tune models using [Tinker](https://thinkingmachines.ai/tinker/), a fine-tuning platform from Thinking Machines. Each team gets $100 in API credits. You upload training data, pick a base model (e.g. Qwen 4B, Llama 8B), and run supervised or RL fine-tuning jobs through a Python API. A 500-example SFT run on a 4B model costs ~$0.25, so you have room to iterate. Sign up: [auth.thinkingmachines.ai/sign-up](https://auth.thinkingmachines.ai/sign-up) Examples: [Tinker Cookbook](https://github.com/thinking-machines-lab/tinker-cookbook) --- # ImageNet .cols[ .col-1-2[ 1.2M labeled images, 1000 categories. A standardized benchmark for image classification. 2012: [Krizhevsky, Sutskever & Hinton](https://proceedings.neurips.cc/paper_files/paper/2012/file/c399862d3b9d6b76c8436e924a68c45b-Paper.pdf) train a CNN on two GPUs (AlexNet). Error drops from 26% to 16%. Two years later, every competitive entry was a deep network. ] .col-1-2[ .center.width-100[] ] ] --- # ImageNet is also a hardware story .cols[ .col-1-2[ ConvNets worked partly because convolutions map well onto GPU architectures. GPUs were designed for graphics, but the operations happened to overlap. "Hardware lottery": which research ideas succeed depends on which operations the available hardware makes fast. .small.muted[Hooker, [The Hardware Lottery](https://arxiv.org/abs/2009.06489) (2020)] ] .col-1-2[ .center.width-90[] .small.muted[Fig 1: [brr](https://hazyresearch.stanford.edu/blog/2024-05-12-tk)] ] ] --- # The RL bet (mid-2010s) Mid-2010s: DeepMind and OpenAI both bet heavily on RL. Documentary (highly recommended!): [The Thinking Game](https://youtu.be/d95J8yzvjbQ?si=6Q7ZTD_FpaU5vV7N&t=872) .cols[ .col-1-2[ - **AlphaGo** (2016): beats Lee Sedol at Go - **AlphaZero** (2017): learns chess, Go, shogi from scratch - **MuZero** (2019): learns the rules of the game itself - **OpenAI Five** (2018–2019): Dota 2 at professional level - **Dactyl** (2018–2019): [robotic hand solves a Rubik's cube](https://openai.com/index/solving-rubiks-cube/?video=776385143) - **Agent 57** (2020): learns 57 Atari games from pixels ] .col-1-2[ .center.width-70[] ] ] --- # The transformer (2017) .cols[ .col-1-2[ .center.width-9080[] A general-purpose sequence model based on the attention mechanism. (We'll cover the architecture in detail in L21!) ] .col-1-2[ .center.width-70[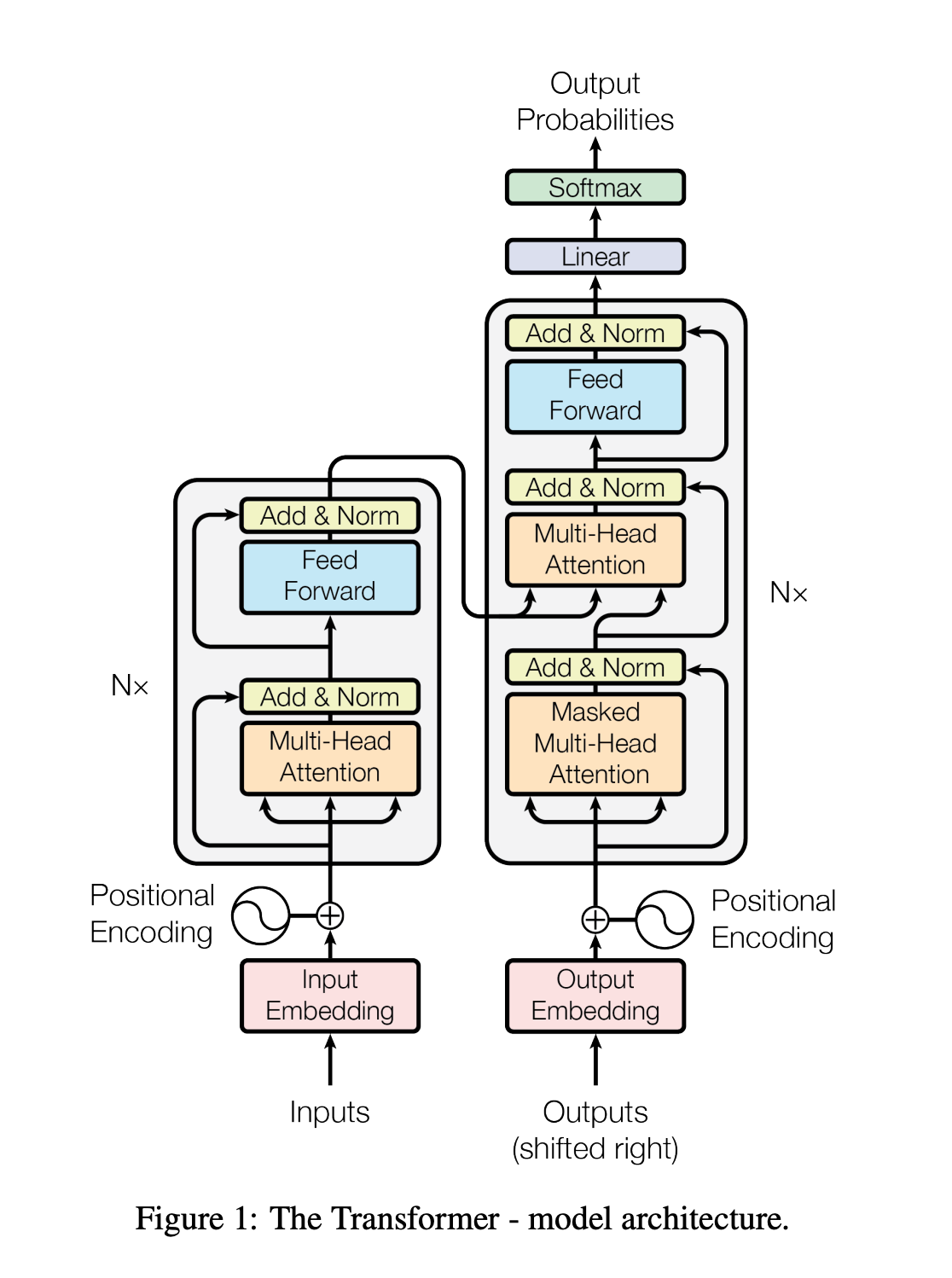] ] ] --- # ViT: transformers for vision (2020) .cols[ .col-1-2[ Dosovitskiy et al. (2020): chop an image into patches, treat each patch as a token, apply a standard transformer. No convolutions or translation invariance baked in, instead learn spatial structure from data. With enough data and compute, ViT matched or exceeded the best CNNs. ] .col-1-2[ .center.width-100[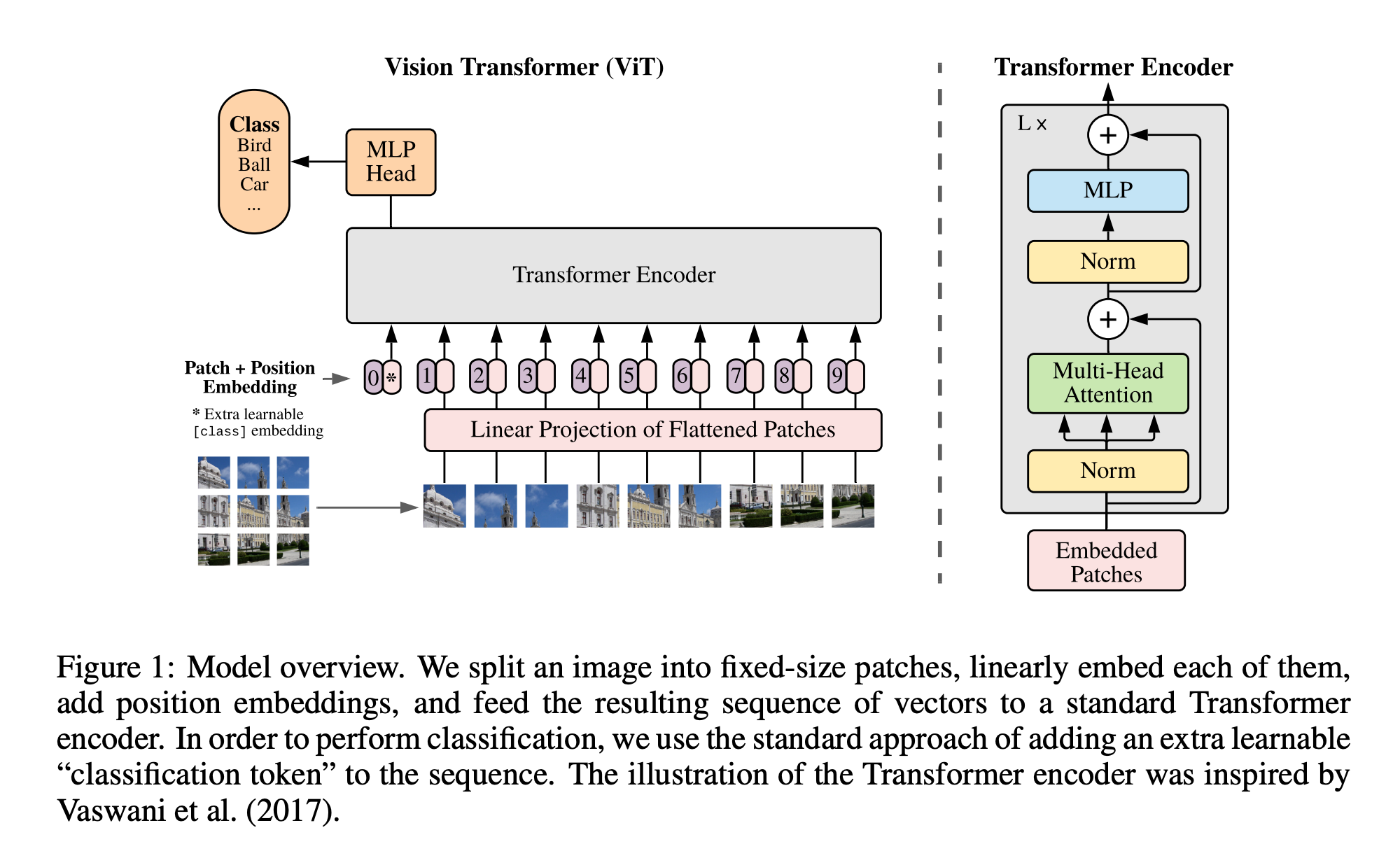] .small.muted[Dosovitskiy et al. (2020)] ] ] --- # Deep learning in 2018 .cols[ .col-1-4[ .center.width-100[] .center[Images] ] .col-1-4[ .center.width-100[] .center[Graphs] ] .col-1-4[ .center.width-100[] .center[Sequences] ] .col-1-4[ .center.width-100[] .center[Language] ] ] --- # Deep learning in 2023 .cols[ .col-1-4[ .center.width-100[] .center[Images] ] .col-1-4[ .center.width-100[] .center[Graphs] ] .col-1-4[ .center.width-100[] .center[Sequences] ] .col-1-4[ .center.width-100[] .center[Language] ] ] --- # Transformer "won" the AI lottery As hardware gets more specialized for transformers (TPUs, custom accelerators), it becomes harder for alternative architectures to compete. The hardware and the research agenda co-evolve! .cols[ .col-1-2[ .center.width-95[] ] .col-1-2[ .center.width-90[] ] ] .footnote[https://www.nvidia.com/en-us/data-center/technologies/blackwell-architecture/] --- # GPT-2: zero-shot transfer (2019) GPT-2 (up to 1.5B params) demonstrated that a language model trained on diverse web text could perform **zero-shot task transfer**: do multiple tasks well without any task-specific data or training. .center.width-70[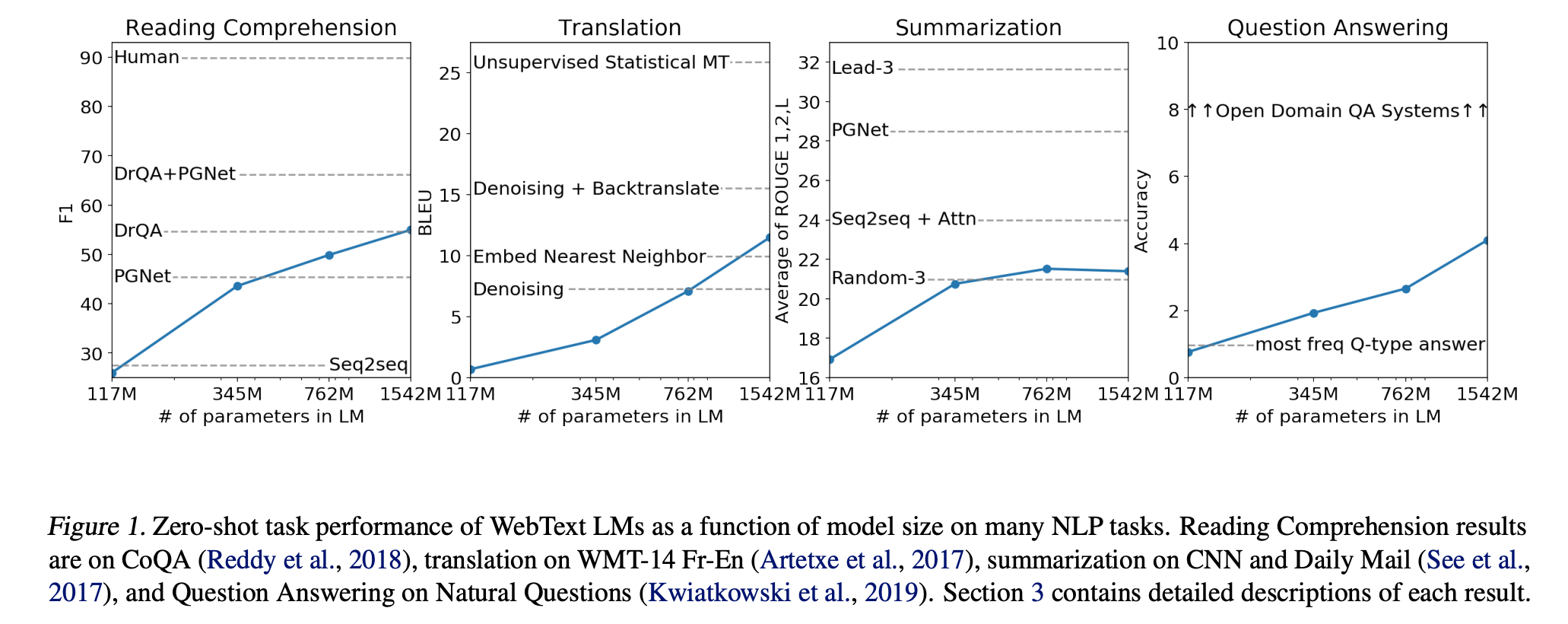] .small.muted[Radford et al., Language Models are Unsupervised Multitask Learners (2019)] --- # Zero-shot, one-shot, few-shot learning .center.width-50[] --- # GPT-3: in-context learning (2020) GPT-3 (175B): **few-shot learning** emerges at scale and rivals fine-tuned and specialized models. .cols[ .col-1-2[ .center.width-100[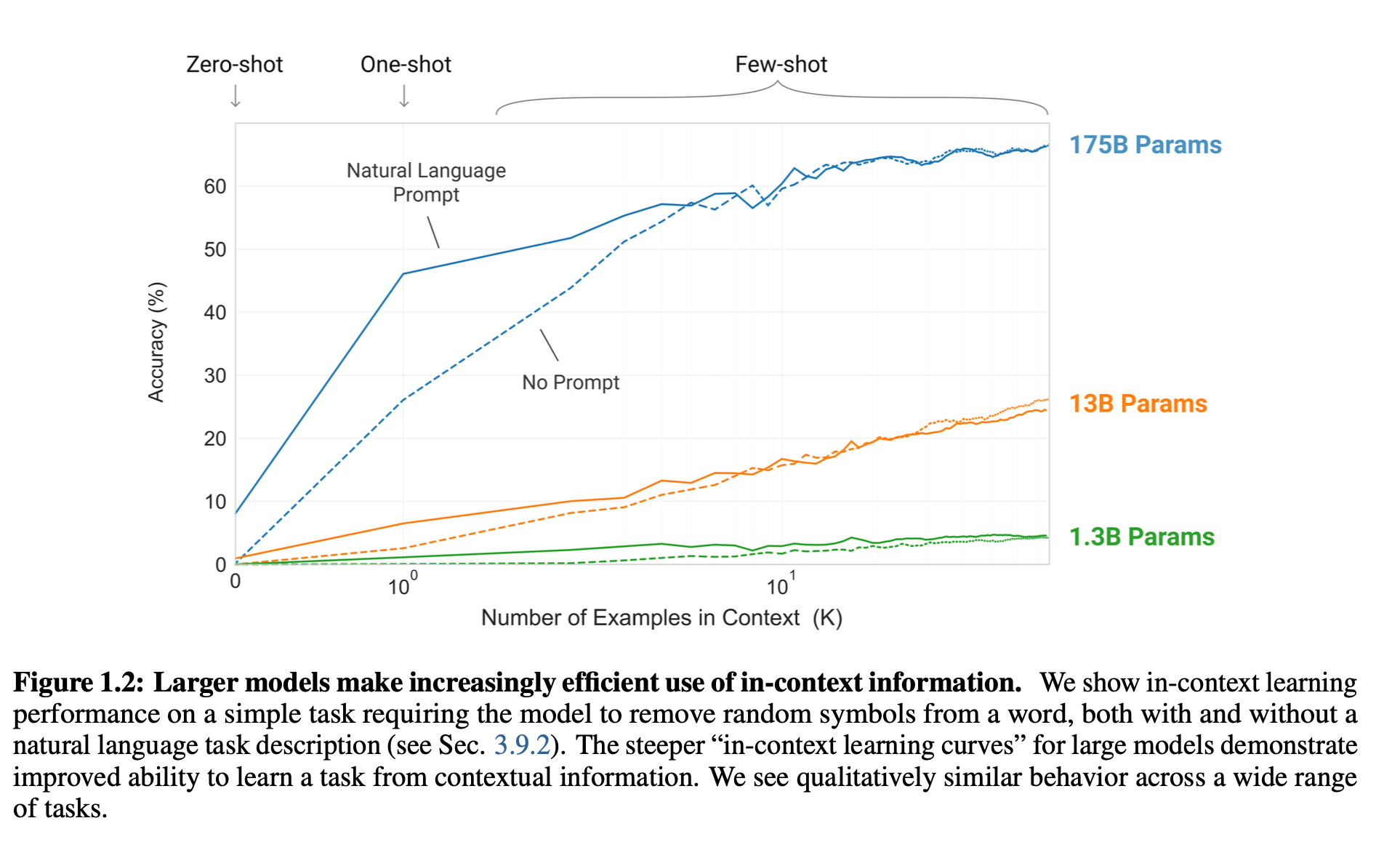] ] .col-1-2[ .center.width-100[] ] ] .small.muted[Brown et al., Language Models are Few-Shot Learners (2020)] --- # Scaling of performance with compute .center.width-70[] --- # Scaling laws Loss improves as a smooth power law in parameters, tokens, and compute. The return on investment is predictable! .cols[ .col-1-2[ .center.width-100[] ] .col-1-2[ $L(N) \propto N^{-0.076}$; $L(D) \propto D^{-0.095}$ Given a fixed compute budget, should you spend it on a bigger model or more data? (more later...) ] ] .small.muted[Kaplan et al., Scaling Laws for Neural Language Models (2020)] --- # The foundation model recipe .cols[ .col-1-2[ 1. **Pre-training**: predict the next token, self-supervised. 2. **Supervised fine-tuning (SFT)**: train on curated (prompt, response) pairs. 3. **RL**: train with RL against a preference model and/or verifiable rewards. ] .col-1-2[ .center.width-90[] .small.muted[LeCun, NeurIPS 2016 keynote (somewhat outdated)] ] ] We'll cover these in detail in L22 (pre-training, SFT) and L23 (RL). --- # [The Bitter Lesson](http://www.incompleteideas.net/IncIdeas/BitterLesson.html) > "The biggest lesson that can be read from 70 years of AI research is that general methods that leverage computation are ultimately the most effective, and by a large margin." > > — Rich Sutton (2019) Common misreading: scale is all that matters, algorithms don't. Better reading: **algorithms that scale are what matter.** --- # Accuracy = efficiency x resources Efficiency matters *more* at larger scales, not less. You can't afford to be wasteful when a training run costs millions of dollars. The right framing: given a fixed compute and data budget, what is the best model you can build? .center.width-50[] .small.muted[From [horace.io/brrr\_intro](https://horace.io/brrr_intro.html)] --- # The Bitter Lesson in practice .cols[ .col-1-2[ - .green[2022]: [Minerva](https://arxiv.org/abs/2206.14858) — math-specific model, state of the art - .red[2023]: [GPT-4](https://arxiv.org/abs/2303.08774) — general-purpose, matched or exceeded Minerva - .green[2024]: [Specialized math systems (AlphaProof) got IMO silver](https://deepmind.google/blog/ai-solves-imo-problems-at-silver-medal-level/) - .red[2025]: [Generalist model got gold](https://deepmind.google/blog/advanced-version-of-gemini-with-deep-think-officially-achieves-gold-medal-standard-at-the-international-mathematical-olympiad/) ] .col-1-2[ .center.width-100[] .small.muted[Bubeck et al., Sparks of AGI (2023)] ] ] --- # The rest of this course **L20**: Quantifying LLM scientific capabilities (evals) **L21**: The transformer (attention, architecture) **L22**: Building a world model (pre-training, tokenization, SFT) **L23**: Learning from feedback and experience (RLHF, RLVR) **L24**: Looking inside the black box (mechanistic interpretability) **L25**: Buffer / final project work --- class: center, middle .big[Next time: **Quantifying LLM Scientific Capabilities**]