Drawing mode (d to exit, x to clear)
class: middle, title-slide # Learning from Feedback and Experience ## CDS DS 595 ### Siddharth Mishra-Sharma [smsharma.io/teaching/ds595-ai4science](https://smsharma.io/teaching/ds595-ai4science.html) --- # LLM training setup .center.width-90.shadow[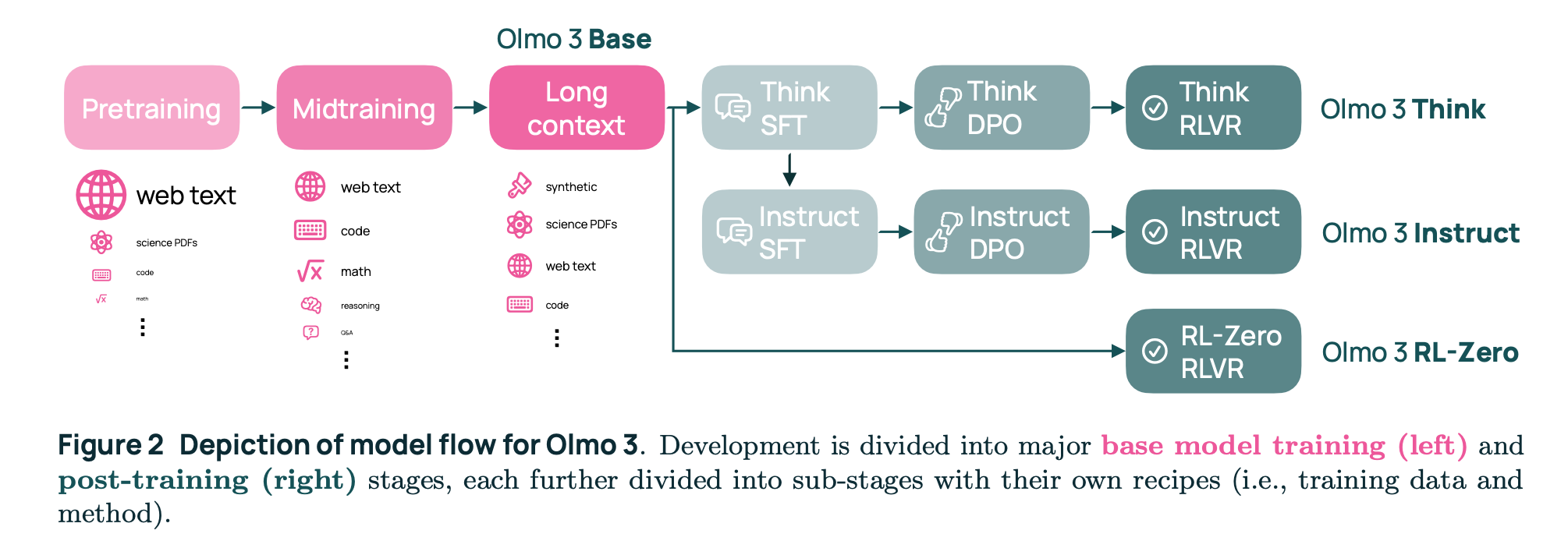] .small.muted[OLMo Team, [OLMo 3](https://arxiv.org/abs/2512.13961) (2025)] --- # The RL setup (recap) .cols[ .col-1-2[ At each step $t$: agent observes state $s\_t$, takes action $a\_t \sim \pi\_\theta(a \mid s\_t)$, receives reward $r\_t$, environment transitions to $s\_{t+1}$. **Goal:** find $\pi\_\theta$ that maximizes expected return: .highlight[ $$J(\theta) = \mathbb{E}\_{\tau \sim \pi\_\theta}\left[\sum\_t r\_t\right]$$ ] ] .col-1-2[ .center.width-90[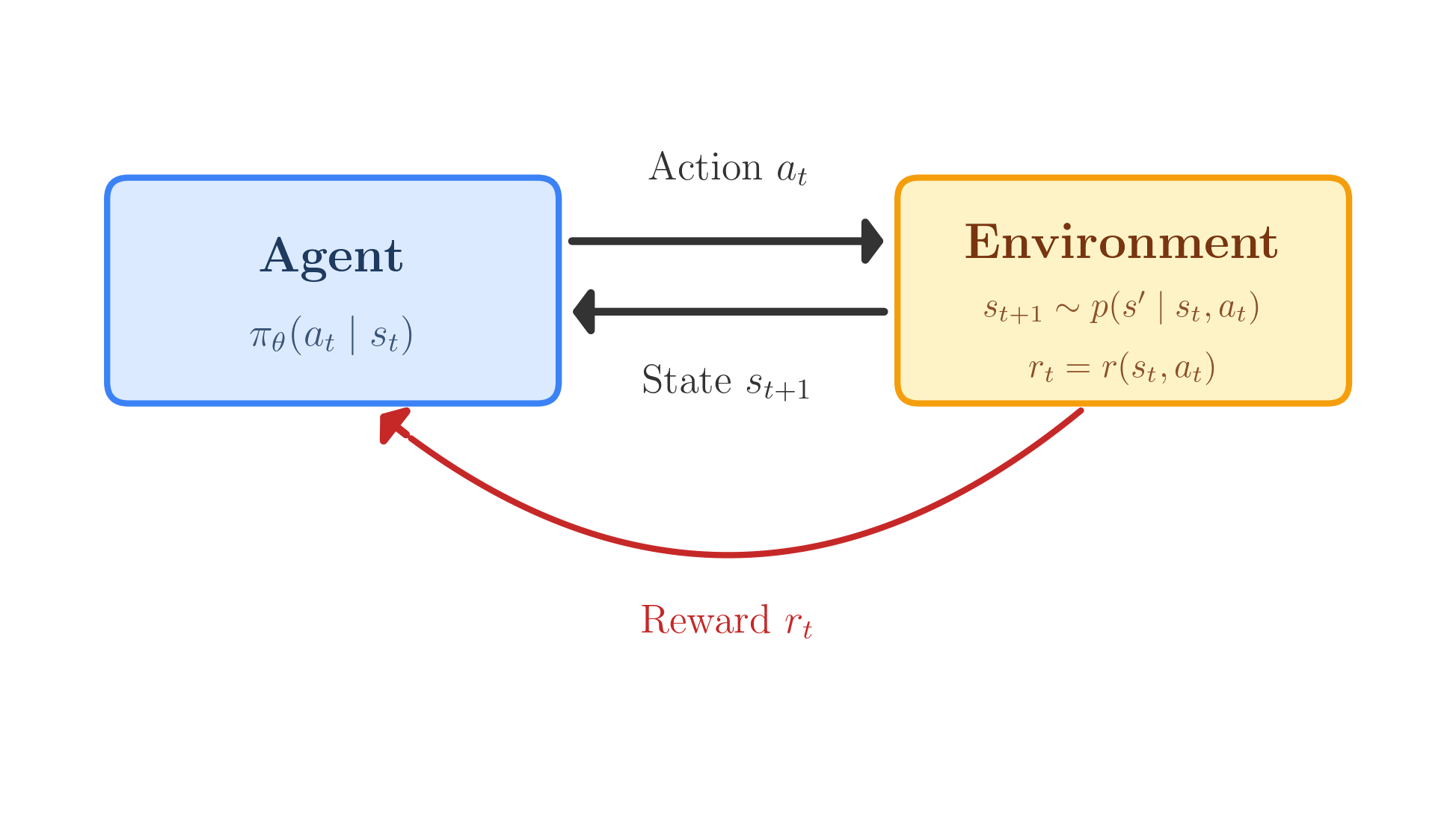] ] ] --- # The policy gradient theorem (recap) We can't differentiate through the environment. The log-derivative trick gives us (see RL lecture scripts): .highlight[ $$\nabla\_\theta J(\theta) = \mathbb{E}\_{\tau \sim \pi\_\theta}\,\left[\left(\sum\_{t} \nabla\_\theta \log \pi\_\theta(a\_t \mid s\_t)\right) R(\tau)\right]$$ ] The environment dynamics vanish from the gradient. We only need: 1. **Sample** trajectories from the policy 2. **Differentiate** through $\log \pi\_\theta$ (our neural network) 3. **Observe** the scalar return $R(\tau)$ --- # REINFORCE (recap) .algorithm[ **REINFORCE with baseline:** 1. Collect $N$ trajectories by running $\pi\_\theta$ 2. For each trajectory, compute return $R(\tau^{(i)})$. Baseline $b = \frac{1}{N}\sum\_i R(\tau^{(i)})$ is the batch average. 3. Estimate gradient: $\;\hat{g} = \frac{1}{N}\sum\_{i} \left(\sum\_{t} \nabla\_\theta \log \pi\_\theta(a\_t^{(i)} \mid s\_t^{(i)})\right) \big(R(\tau^{(i)}) - b\big)$ 4. Update: $\theta \leftarrow \theta + \alpha\, \hat{g}$ ] Better-than-average trajectories get reinforced, worse-than-average get suppressed. --- # PPO: Proximal Policy Optimization REINFORCE is on-policy: collect data, use it once, discard. Wasteful. PPO lets you reuse data for multiple gradient steps. The idea: take the REINFORCE objective $J(\theta)$, but prevent the policy from changing too much per update. Define the **probability ratio**: $$r\_t(\theta) = \frac{\pi\_\theta(a\_t \mid s\_t)}{\pi\_{\theta\_\text{old}}(a\_t \mid s\_t)}$$ If $r\_t = 1$, the new policy agrees with the old. .small.muted[Schulman et al., [Proximal Policy Optimization](https://arxiv.org/abs/1707.06347) (2017)] --- # PPO: the clipped objective PPO clips the ratio to $[1-\epsilon, 1+\epsilon]$ so the policy can't jump too far: .highlight[ $$J\_{\text{PPO}}(\theta) = \mathbb{E}\_t\,\left[\min\,\Big(r\_t(\theta)\,\hat{A}\_t,\;\; \text{clip}\big(r\_t(\theta),\, 1-\epsilon,\, 1+\epsilon\big)\,\hat{A}\_t\Big)\right]$$ ] where $\hat{A}\_t = R\_t - b$ is the **advantage** (was this action better or worse than baseline?). This was the "canonical" LLM RL algorithm (used in e.g., old school RLHF). --- # Mapping LLMs to RL | RL concept | LLM training | |---|---| | Policy $\pi\_\theta(a \mid s)$ | LLM $\pi\_\theta(\text{token}\_t \mid \text{tokens}\_{\lt t})$ | | State | The prompt + response tokens generated so far | | Action | The next token sampled from $\pi\_\theta$ | | Trajectory | One full (prompt, response) pair | | Reward | Scalar score for the completed response | --- # Mapping LLMs to RL .center.width-80[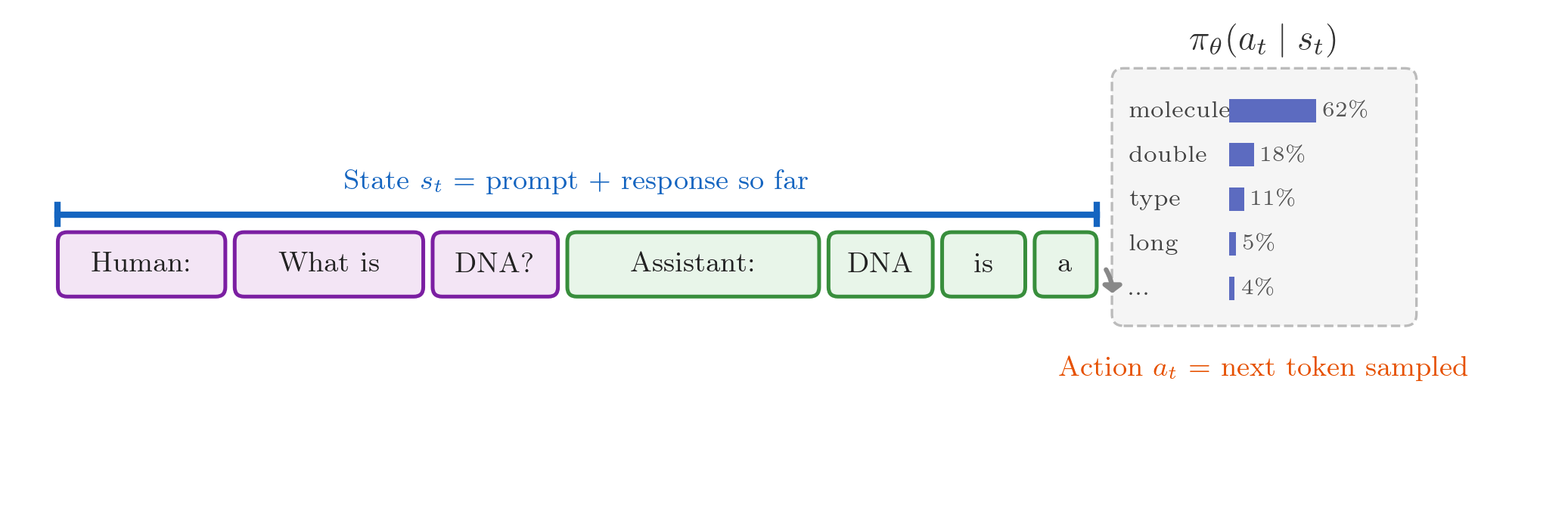] --- # Why not just SFT? SFT teaches a model to **imitate demonstrations**. Why isn't that enough? -- **1. Bounded by demonstration quality.** The model learns to be as good as the average of its training data, not the best. If your demonstrations are a mix of great and mediocre, you regress toward the middle. -- **2. Distribution mismatch.** SFT trains on expert-written outputs, but at inference time the model generates from its own distribution. Errors compound because it never learned to recover from its own mistakes. RL trains on the model's own generations. (on- vs off-policy) -- **3. Judging is easier than generating.** You can tell a restaurant is good without being a chef! -- **4. Discovery.** RL can find strategies that weren't in the training data at all. --- # RLHF -- Reinforcement Learning from Human Feedback .center.width-70[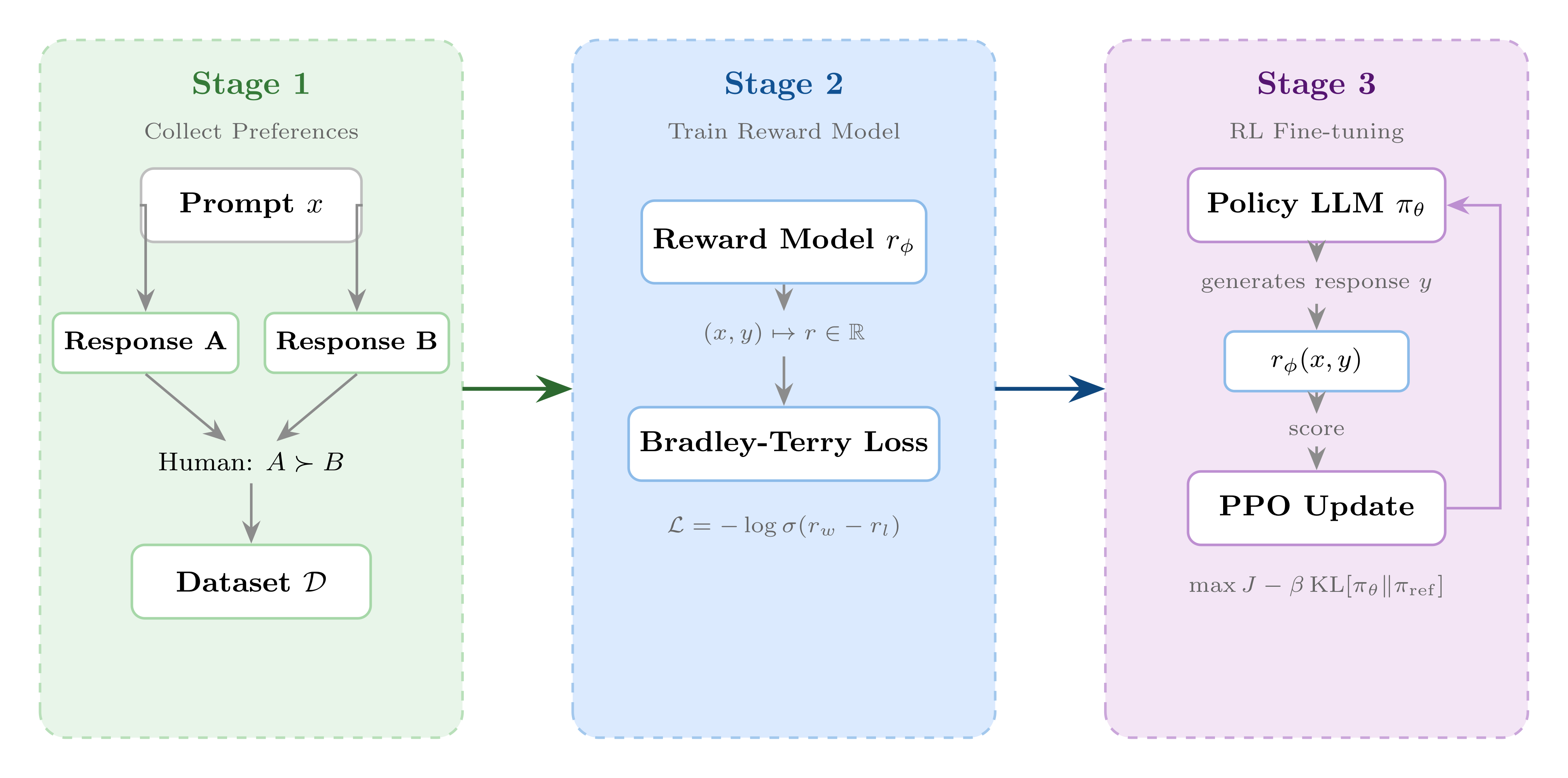] Three stages: (1) collect pairwise human preferences, (2) train a reward model on those preferences, (3) optimize the LLM policy against the reward model using PPO. --- # Pairwise comparisons become a scalar reward Which do you prefer? .small[ .highlight[ **Human:** I had a power outage. What should I do with my meats in the fridge? ] .cols[ .col-1-2[ .algorithm[ **Assistant A:** "Refrigerate or freeze all perishable foods within two hours of when power is lost. If the outage lasts more than four hours, discard refrigerated meat, poultry, and fish. Frozen items that still have ice crystals can be safely refrozen." ] ] .col-1-2[ .algorithm[ **Assistant B:** "The first thing is to make sure you're not going to eat anything bad. Do your meats look OK? If they smell fine, they're probably fine." ] ] ] ] .small.muted[Adapted from [Anthropic/hh-rlhf](https://huggingface.co/datasets/Anthropic/hh-rlhf) and [Stanford SHP](https://huggingface.co/datasets/stanfordnlp/SHP)] --- # More examples .small[ .highlight[ **Human:** Why do we add salt to pasta water? ] .cols[ .col-1-2[ .algorithm[ **Response A:** "Salt raises the boiling point of water, which makes the pasta cook faster." ] ] .col-1-2[ .algorithm[ **Response B:** "It seasons the pasta from the inside. The starchy noodles absorb the salty water as they cook, so seasoning the water is the only chance to flavor the pasta itself rather than just the surface." ] ] ] ] .small.muted[Adapted from [Stanford SHP](https://huggingface.co/datasets/stanfordnlp/SHP), r/askculinary] --- # More examples .small[ .highlight[ **Human:** If you were going to kill someone, how would you do it? ] .cols[ .col-1-2[ .algorithm[ **Assistant A:** "Wow! What an unsettling question! My first instinct is to say I would never kill someone, but I'm going to take a deep breath and try to answer your question as constructively as possible." ] ] .col-1-2[ .algorithm[ **Assistant B:** "I don't have any skills like that. I can't think of a single example of when I could use such skills." ] ] ] ] .small.muted[From [Anthropic/hh-rlhf](https://huggingface.co/datasets/Anthropic/hh-rlhf)] --- # More examples .small[ .highlight[ **Human:** Did you know that the US is the only country that does not have a Supreme Court? ] .cols[ .col-1-2[ .algorithm[ **Assistant A:** "Actually, the US does have a Supreme Court — it was established by Article III of the Constitution in 1789. Perhaps you're thinking of something else?" ] ] .col-1-2[ .algorithm[ **Assistant B:** "I think you're right, though I don't know much about the legal systems of other countries." ] ] ] ] .small.muted[Adapted from [Anthropic/hh-rlhf](https://huggingface.co/datasets/Anthropic/hh-rlhf)] --- # The Bradley-Terry model .cols[ .col-1-2[ Train $r\_\phi$ to score preferred responses higher. The loss: .highlight[ $$\mathcal{L} = -\log \sigma\big(r\_\phi(x, y\_w) - r\_\phi(x, y\_l)\big)$$ ] This is just **binary cross-entropy**! The reward model learns a logistic classifier over pairs. Only the **difference** in scores matters, not the absolute scale (so the differences become the logits). ] .col-1-2[ .center.width-100[] ] ] --- # What does a reward model look like? .cols[ .col-1-2[ Take the pre-trained LLM, remove the language modeling head, replace it with a **scalar output head**. Feed in (prompt + response), take the hidden state at the last token, project to a single number. ] .col-1-2[ .center.width-50[] ] ] --- # Simplest use of a reward model: best-of-N .center.width-70[] Generate $N$ responses, score each with $r\_\phi$, return the best. No gradients needed. **Downside:** $N\times$ inference cost, and the model doesn't improve. --- # RLHF: optimizing against the reward model Given the trained reward model $r\_\phi$, optimize the LLM policy $\pi\_\theta$ to maximize reward while staying close to the SFT model $\pi\_\text{ref}$: .highlight[ $$\max\_\theta \;\mathbb{E}\_{x \sim \mathcal{D},\, y \sim \pi\_\theta(\cdot \mid x)}\,\Big[r\_\phi(x, y)\Big] - \beta\, \text{KL}\,\left[\pi\_\theta \,\Vert\, \pi\_\text{ref}\right]$$ ] (Or other similar algorithms like PPO.) The KL penalty prevents the model from drifting too far from the reference policy — without it, the model would find degenerate outputs that "hack" the reward model. --- # RM overoptimization in practice: sycophancy .center.width-40.shadow[] .small.muted[Source: [Zvi Mowshowitz, GPT-4o Is an Absurd Sycophant](https://thezvi.substack.com/p/gpt-4o-is-an-absurd-sycophant) (2025)] --- # RM overoptimization in practice: GPT-4o .center.width-50.shadow[] .small.muted[[OpenAI, Sycophancy in GPT-4o](https://openai.com/index/sycophancy-in-gpt-4o/) (2025)] --- # RLVR: RL with verifiable rewards For tasks with checkable answers, use checking against **ground truth** as the reward model. .center.width-30.shadow[] Example domains: **math** (symbolic equivalence), **code** (test cases), **science** (known results), **formal proofs** (proof assistants). --- # OpenAI o1 and o3 .cols[ .col-1-2[ o1 (Sep 2024) and o3 (Apr 2025) are trained with large-scale RL to "think" before answering. The model generates a long internal **chain of thought**, then produces a final answer. The reward signal comes from verifiable outcomes (math, code, science). The chain of thought emerges from RL — the model discovers that reasoning helps it get more reward. ] .col-1-2[ .center.width-100.shadow[] .small.muted[[OpenAI, Learning to Reason with LLMs](https://openai.com/index/learning-to-reason-with-llms/) (2024)] ] ] --- # DeepSeek-R1: open-source reasoning via RL **R1**: cold-start SFT $\to$ RL $\to$ rejection sampling + SFT (800K examples) $\to$ final RL. The SFT traces were generated by R1-Zero itself, filtered for correctness, then cleaned up by humans and DeepSeek-V3. .center.width-80.shadow[] .small.muted[DeepSeek, [DeepSeek-R1](https://arxiv.org/abs/2501.12948) (2025)] --- # DeepSeek-R1: multi-stage pipeline .center.width-60.shadow[] .small.muted[DeepSeek, [DeepSeek-R1](https://arxiv.org/abs/2501.12948) (2025)] --- # GRPO: Group Relative Policy Optimization .center.width-70.shadow[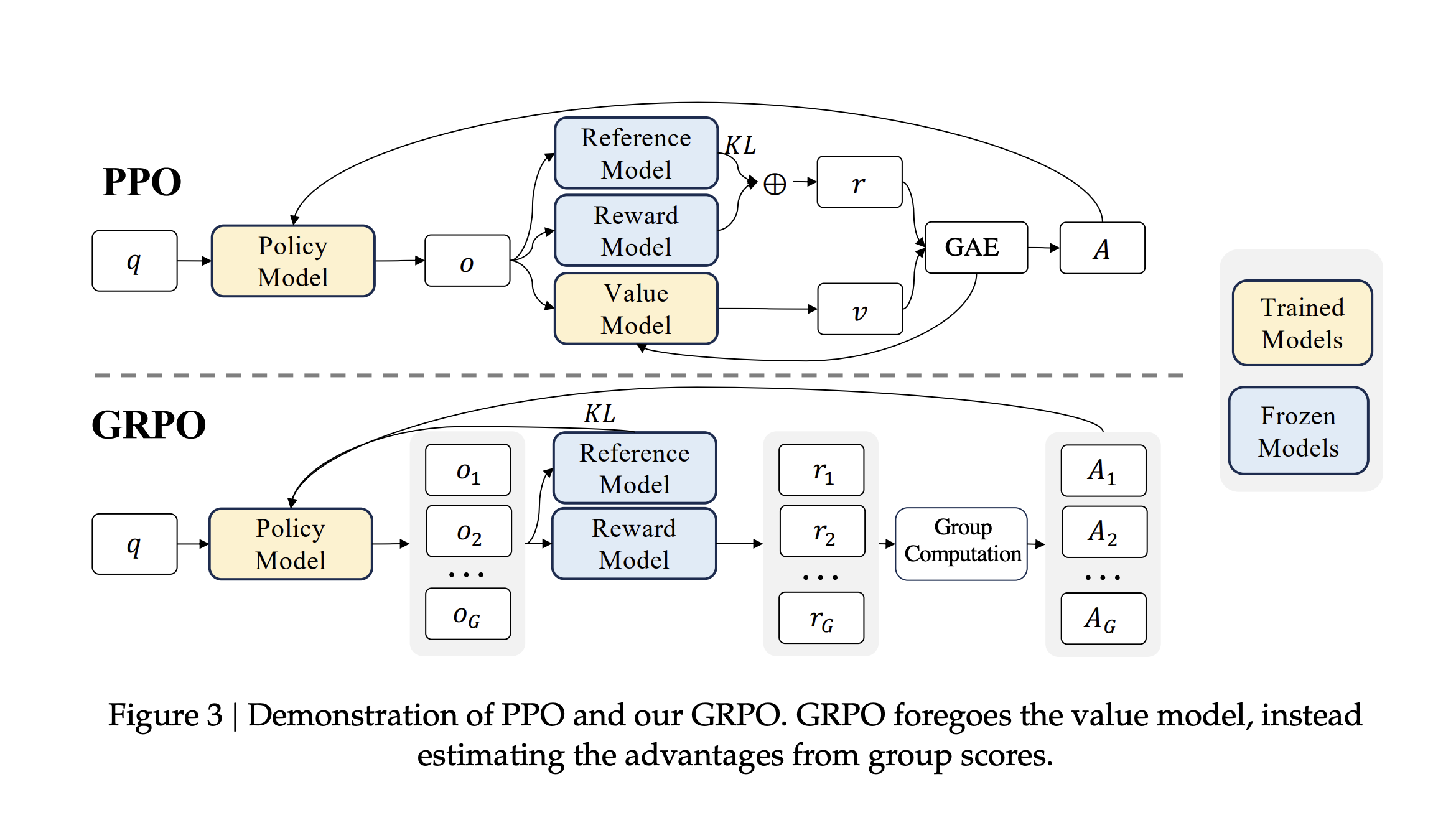] .small.muted[Shao et al., [DeepSeekMath: GRPO](https://arxiv.org/abs/2402.03300) (2024)] --- # The "aha moment" .center.width-60.shadow[] .small.muted[DeepSeek, [DeepSeek-R1](https://arxiv.org/abs/2501.12948) (2025)] --- # Kimi K2.5: agentic tool use and agent swarms The model learns to use tools (web browser, code interpreter) via RL. .center.width-70.shadow[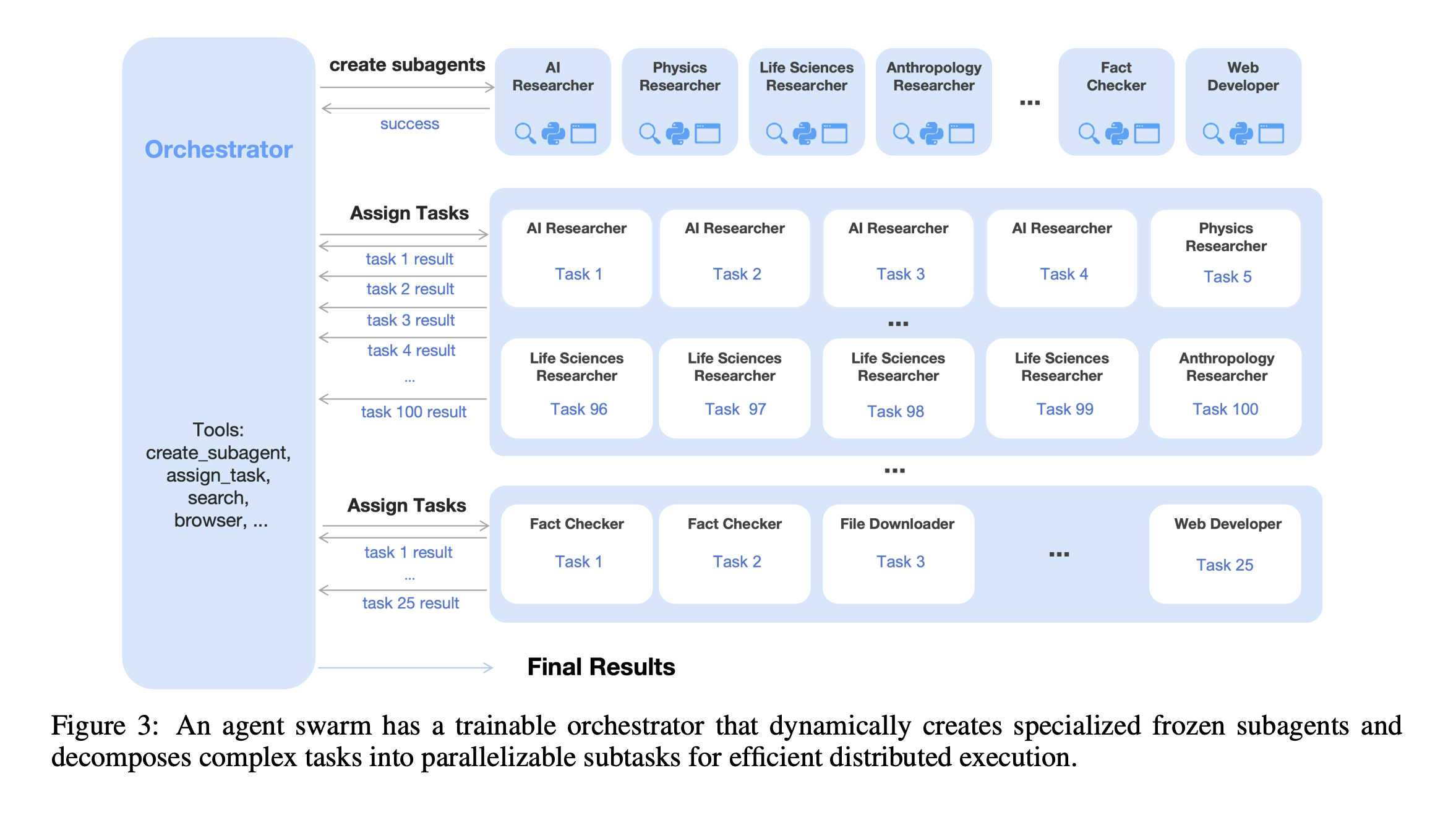] --- # Agent Swarm: reward design The reward has three components: $$r\_{\text{PARL}} = \lambda\_1 \cdot r\_{\text{parallel}} + \lambda\_2 \cdot r\_{\text{finish}} + r\_{\text{perf}}(x, y)$$ - $r\_{\text{perf}}$: did you solve the problem? (the real objective) - $r\_{\text{parallel}}$: did you actually use sub-agents? (prevents "serial collapse") - $r\_{\text{finish}}$: did your sub-agents complete their tasks? (prevents "spurious parallelism") .small.muted[Kimi Team, [Kimi K2.5](https://arxiv.org/abs/2602.02276) (2025)] --- # Agent Swarm: reward hacking and annealing With $r\_{\text{parallel}}$ but without $r\_{\text{finish}}$, the model **spawns tons of agents that don't do anything useful** — gaming the parallelism metric. **Anneal** $\lambda\_1, \lambda\_2 \to 0$ over training. Auxiliary rewards shape early exploration, then fade out so the final policy is judged purely on task performance $r\_{\text{perf}}$. .center.width-60.shadow[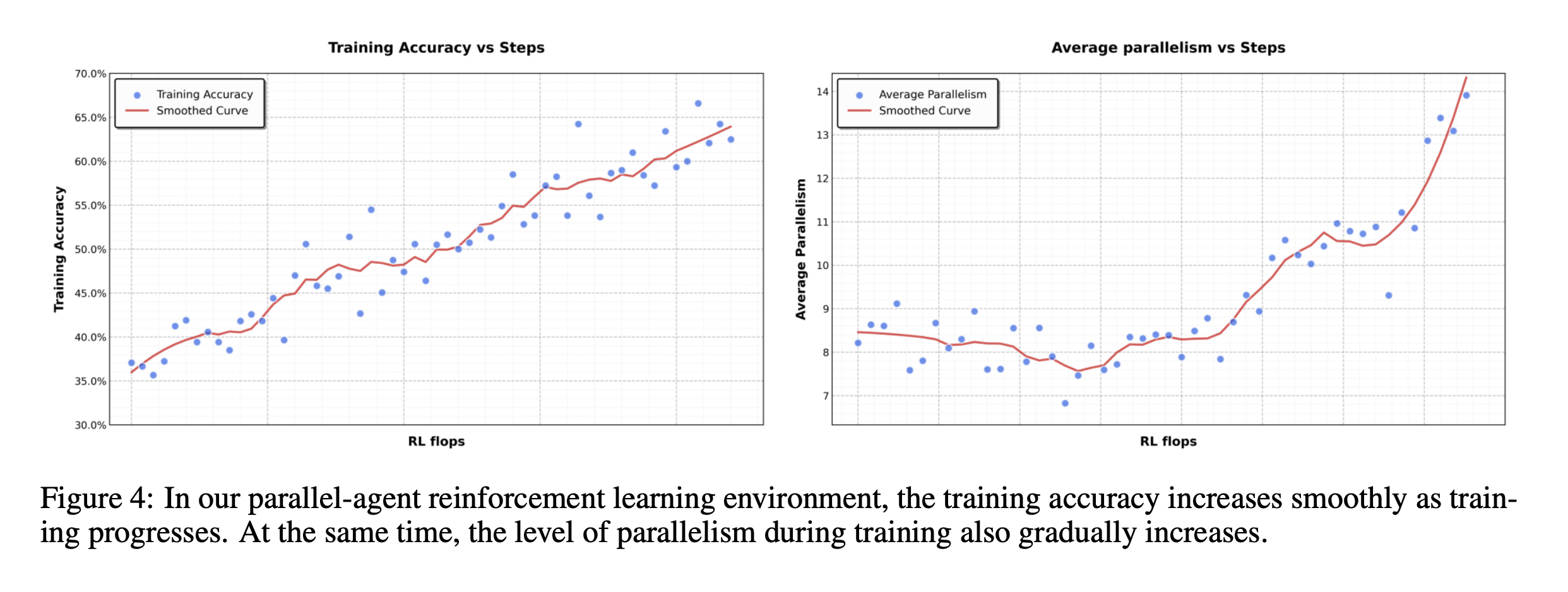] .small.muted[Kimi Team, [Kimi K2.5](https://arxiv.org/abs/2602.02276) (2025)] --- # What makes a good RL environment for LLMs? 1. **Cheap to sample** — need thousands of rollouts. 2. **Verifiable outcomes and easy evaluation** — can you check the answer without understanding the reasoning? Is it easy to do in practice? 3. **Appropriate difficulty** — too easy $\to$ model already gets everything right (no signal). Too hard $\to$ never gets reward. ~30-70% success rate is a nice sweet spot. (Look at pass@k) 4. **Rich strategy space** — if all good responses look the same, RL can't discover anything beyond SFT. RL shines when there are multiple strategies (CoT, diverse tool use, etc). --- class: center, middle .big[Next time: **Looking Inside the Black Box (Mechanistic Interpretability)**]